

Proces Kafka to popularny system do przesyłania i przetwarzania strumieni danych w czasie rzeczywistym. Dzięki swojej wydajności, niezawodności i skalowalności zyskał szerokie zastosowanie w wielu firmach i organizacjach. W tym artykule przyjrzymy się bliżej działaniu i zaletom tego rozwiązania oraz omówimy krok po kroku jak wdrożyć proces Kafka.
Kluczowe wnioski:- Proces Kafka cechuje się dużą przepustowością i niezawodnością przesyłania danych.
- Łatwo go skalować w miarę rozwoju Twojej firmy.
- Integruje się z wieloma popularnymi systemami i narzędziami.
- Pozwala budować elastyczne systemy przetwarzania danych w czasie rzeczywistym.
- Instalacja i konfiguracja nie są skomplikowane.
Proces Kafka - co to jest?
Kafka to popularny system do budowy potoków przetwarzania danych w czasie rzeczywistym. Został stworzony w firmie LinkedIn w 2011 roku, a obecnie jest projektem open source rozwijanym przez firmę Confluent.
Kafka umożliwia przesyłanie i przetwarzanie ogromnych ilości danych w postaci strumieni z zachowaniem ich kolejności. Dane te mogą pochodzić z wielu źródeł, np. aplikacji, serwerów, czujników internetu rzeczy. Kafka gromadzi je w swoich magazynach zwanych topicami, skąd mogą być pobierane przez różne systemy i aplikacje.
Kluczowe cechy Kafka to:
- wysoka przepustowość,
- skalowalność,
- odporność na awarie,
- zapewnienie kolejności przetwarzania danych.
Dzięki temu sprawdza się zarówno w małych, jak i ogromnych systemach przetwarzających miliony zdarzeń na sekundę.
Zastosowania Kafki
Kafka jest wykorzystywany w wielu obszarach, gdzie liczy się szybki dostęp do danych w czasie rzeczywistym, np.:
- Systemy monitorowania i zbierania danych (logi, metryki)
- Przetwarzanie transakcji online
- Analiza zachowań użytkowników
- Przesyłanie danych między systemami i mikrousługami
Jest też często wykorzystywany wraz z popularnymi technologiami do przetwarzania danych, takimi jak Spark, Flink czy Elasticsearch.
Jak działa proces Kafka?
Kafka działa w oparciu o architekturę publish-subscribe. Oznacza to, że dane są publikowane do topiców, z których konsumenci mogą je subskrybować zgodnie ze swoimi potrzebami.
Publikowanie i konsumowanie odbywa się asynchronicznie, co zapewnia wysoką wydajność i niezawodność. Kafka buforuje przesyłane dane, dzięki czemu konsumenci mogą je odbierać we własnym tempie.
Kluczowe elementy architektury Kafka:
- Producenci - publikują dane do topiców
- Konsumenci - subskrybują dane z topiców
- Topici (topics) - kategorie lub strumienie danych
- Brokerzy (brokers) - serwery przechowujące dane
Dane wypływają od producentów do brokerów i topiców, skąd są pobierane przez konsumenów. Brokerzy tworzą klaster, który może być elastycznie skalowany w miarę rozwoju systemu.
Przetwarzanie danych
Kafka gwarantuje przetwarzanie każdego zdarzenia dokładnie raz, z zachowaniem kolejności. Służą temu mechanizmy takie jak:
- Offsety - unikalne numery kolejnych zdarzeń w topiku
- Potwierdzanie offsetów - konsumenci informują, do którego offsetu odczytali dane
- Replikacja - Kafka utrzymuje repliki każdego topiku na wielu brokerach
Dzięki temu nawet w przypadku awarii system może kontynuować przetwarzanie danych bez utraty ciągłości i spójności.
Czytaj więcej: TOP 30+ najlepszych polskich filmów wszech czasów ranking 2023
Zalety procesu Kafka
Kafka oferuje szereg zalet, które decydują o jego popularności:
Wysoka wydajność
Kafka został zaprojektowany od podstaw z myślą o przetwarzaniu dużych wolumenów danych. Pozwala na miliony zapisów i odczytów na sekundę przy stosunkowo niskim opóźnieniu rzędu kilku milisekund.
Skalowalność
Klaster Kafka można łatwo rozszerzać o kolejne węzły, co umożliwia horyzontalne skalowanie. Pozwala to sprostać rosnącym wymaganiom wydajnościowym wraz z rozwojem systemu.
Niezawodność
Kafka gwarantuje przetworzenie każdego zdarzenia oraz zachowanie ich kolejności. Chroni to przed utratą kluczowych danych w przypadku awarii.
Łatwa integracja
Kafka udostępnia proste interfejsy API w wielu językach programowania. Dobrze integruje się z rozmaitymi technologiami big data, jak Spark, Flink, Hadoop i bazy danych.
Wady procesu Kafka
Kafka ma też pewne ograniczenia, o których warto pamiętać:
Złożoność
Kafka wymaga zrozumienia dość złożonych koncepcji, jak strumienie czy przetwarzanie rozproszone. Może to wydłużyć czas potrzebny na wdrożenie i efektywne wykorzystanie.
Konieczność tuningu
Aby Kafka działał wydajnie, należy odpowiednio skonfigurować parametry, jak partie czy replikację. Wymaga to testów i optymalizacji pod kątem konkretnego obciążenia.
Brak mechanizmów wyszukiwania
Kafka przechowuje dane tylko przez określony czas. Nie posiada zaawansowanych możliwości wyszukiwania historycznych danych jak bazy danych.
Kafka a inne systemy przesyłu danych
Oprócz Kafki istnieją inne popularne systemy do przesyłania danych, takie jak:
| RabbitMQ | Apache Pulsar | Apache Spark Streaming |
| Opiera się na kolejkach komunikatów. Lżejszy i prostszy od Kafki. | Konkurencyjny do Kafki system pub-sub z podobną funkcjonalnością. | Umożliwia przetwarzanie danych strumieniowych w Sparku. |
Kafka wyróżnia się szczególnie pod kątem wydajności, niezawodności i ekosystemu. Jednak inne rozwiązania mogą być lepsze w mniejszych systemach lub do konkretnych zastosowań.
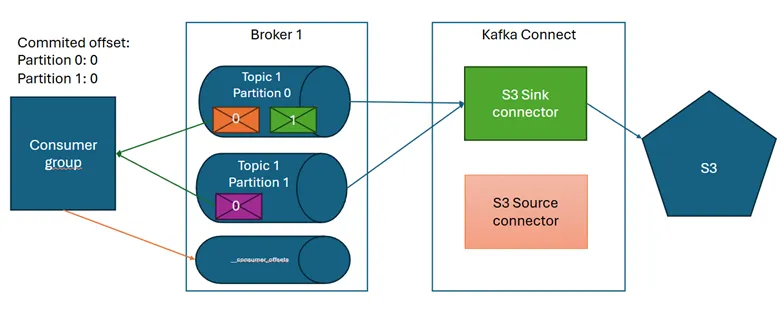
Jak wdrożyć proces Kafka?
Aby wdrożyć Kafkę, należy wykonać następujące kroki:
Zainstaluj Zookeeper
Jest to usługa koordynująca działanie Kafki. Można ją zainstalować na dedykowanych maszynach lub wraz z Kafką.
Zainstaluj brokery Kafki
Brokerzy przechowują i udostępniają dane. Klaster Kafka wymaga co najmniej 3 brokerów. Można zacząć od 1 w środowisku testowym.
Stwórz topiki
Topiki definiują kategorie danych w Kafce. Możesz utworzyć je z poziomu wiersza poleceń lub panelu Control Center.
Uruchom producentów i konsumentów
Producenci publikują dane do topików, konsumenci je konsumują. Można napisać własne lub użyć wbudowanych.
Monitoruj działanie Kafki
Control Center pozwala monitorować wydajność i ułatwia optymalizację parametrów Kafki. Warto też regularnie wykonywać kopie zapasowe.
Dobre zrozumienie działania Kafki i testy pozwolą efektywnie wykorzystać jego możliwości. Jest to potężne rozwiązanie do budowy nowoczesnych systemów bazujących na danych.
Podsumowanie
Proces Kafka to obecnie jedno z najpopularniejszych narzędzi do przetwarzania i analizy strumieni danych. Jego mocną stroną jest wydajność, skalowalność i niezawodność. Dzięki temu sprawdza się zarówno w małych, jak i ogromnych systemach bazujących na data streamingu.
Sekretem popularności Kafki jest stosunkowo prosta architektura oparta o mechanizm publish-subscribe. Kafka odbiera strumień danych, buforuje go i udostępnia do odczytu. To pozwala systemom działać asynchronicznie z zachowaniem wysokiej wydajności.
Jak widzieliśmy, Proces Kafka ma szerokie zastosowanie przy przetwarzaniu danych w czasie rzeczywistym oraz integracji rozproszonych systemów. Warto rozważyć jego wykorzystanie, jeśli Twoja firma buduje nowoczesną architekturę opartą o mikrousługi i potrzebuje niezawodnej komunikacji między nimi.
Oczywiście Kafka ma też pewne ograniczenia, jak złożoność czy konieczność tuningu. Dlatego alternatywne rozwiązania jak RabbitMQ czy Pulsar mogą być lepsze w niektórych scenariuszach. Jednak ogólnie Kafka jest dobrym wyborem przy budowie zaawansowanych systemów do streamowania danych.



